Topics
Content Writing Resources
Language Learning
Consumer Court
Indian Heathy Recipes
Python
Exams
Birds
Books
Music
Meditation
Audio Books
Join Learning Community
Stories
Contact
WhatsApp Group
Topics
Content Writing Resources
Language Learning
Consumer Court
Indian Heathy Recipes
Python
Exams
Birds
Books
Music
Meditation
Audio Books
Join Learning Community
Stories
Contact
WhatsApp Group
What do you want to
Learn
today?
Recipes
Birds
Exams
Content Writing
Meditation
Learn Languages
Stories
Python
Music
Learn Python Online
Learn Languages
Mystery Stories
Beautiful Backyard Birds
Indian Healthy Recipes
Exam Preparation
Learning
to Teach
Meditation
Audio Books
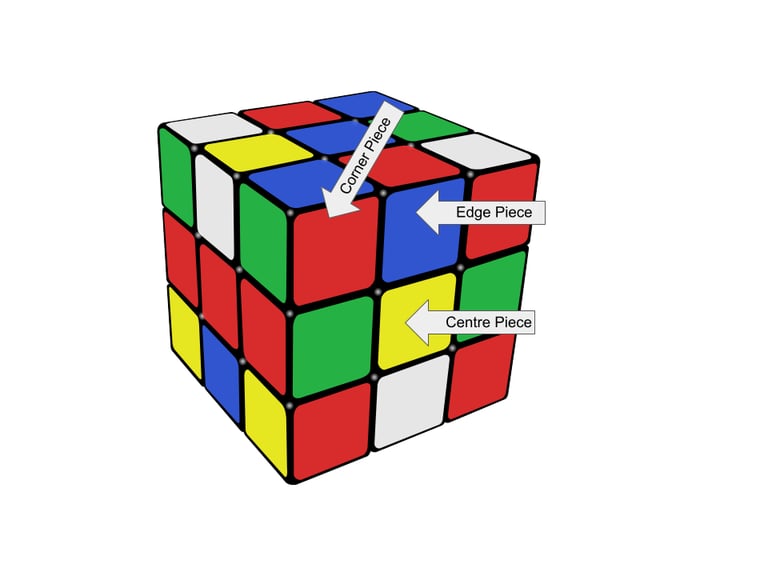
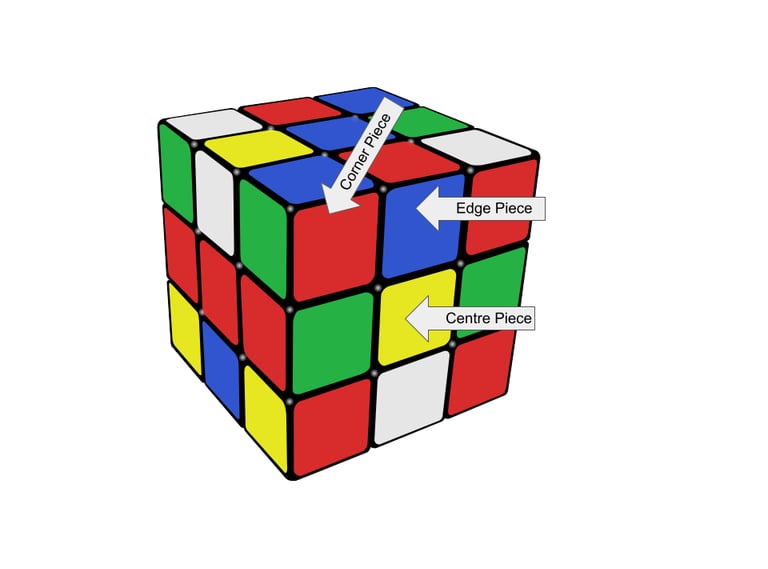
Solve The Cube
Consumer Court
Learn Languages
Music
Learn with Want2Learn
Chandrayaan 3
Consumer Court